GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖99.75%的使用频率。GB2312中对所收汉字进行了“分区”处理,每区含有94个汉字/符号。这种表示方式也称为区位码。
01-09区为特殊符号。
16-55区为一级汉字,按拼音排序。
56-87区为二级汉字,按部首/笔画排序。
10-15区及88-94区则未有编码。
举例来说,“啊”字是GB2312之中的第一个汉字,它的区位码就是1601。字节结构在使用GB2312的程序中,通常采用EUC储存方法,以便 兼容于ASCII。每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”,第二个字节称为“低位字节”。 “高位字节”使用了0xA1-0xF7(把01-87区的区号加上0xA0),“低位字节”使用了0xA1-0xFE(把01-94加上0xA0)。例如 “啊”字在大多数程序中,会以0xB0A1储存。(与区位码对比:0xB0=0xA0+16,0xA1=0xA0+1)。
所以GB2312编码中汉字区码的十进制是从176到247,位码是从161到255.之所以存储了6763小于82*94=6768,是因为在区码为215,位码为250-254之间共五个编码没有汉字编码,所以6768-5=6763个。
GB2312编码可以通俗理解为国内通用的语言。
推荐charset使用编码
UTF-8可以通俗理解简体繁体可用此编码如台湾和内地使用此编码。
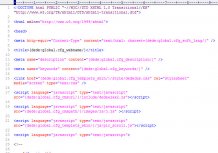
因编码导致网页兼容错误问题:
如果编码混排将使网页乱码也叫不兼容,特别是在CSS注解中使用了编码混排将导致css hack。
希望以后在制作网页的时候千万不要忘记对网页编码的声明。
标签: