DEDE程序核心程序目录及简介+数据表结构简介
dedecms8.com">dede 采集自动文章摘要教程
dede采集文章,过滤规则大全,常用规则
订阅
{dede:trim replace=dede:trim}
过滤后缺少了链接文字,这样使的文章内容不通顺,换成下面这两条,只过滤前面的标记
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
过滤网址为指定的网址
{dede:trim replace= }|cn|net){/dede:trim}
这样可以把文章中的所有域名换成你想要的网址
优化文章标题添加指定的文字头
标题规则:本来是
但是现在很流行关键词再加标题的形式
所以我们可以这样设置
标题规则:
看到没,少了le> 下面就用过滤规则替换掉
{dede:trim replace='QQ空间'}le>{/dede:trim}
这样就做到了任何地方标题前面加了指定的关键字
过滤指定的一些不想要的文字
{dede:trim replace= }晋利达反赌俱乐部{/dede:trim}
这样就把文章里有这些字的地方过滤成空了,不过这样做有时文章会读不通,经常会用到互换
{dede:trim replace= 晋利达俱乐部 }晋利达反赌俱乐部{/dede:trim}
过滤一些电话
过滤400电话
{dede:trim replace= }\d{4}-\d{3}-\d{3}{/dede:trim}
过滤13 15 18开头的手机号
{dede:trim replace= }(13|15|18)\d{9}{/dede:trim}
===================================================================================================
会员中心 收藏本站 网站地图 TAG标签 首页 织梦CMS 帝国CMS PHPCMS PHP168 WordPress CMSTOP 动易CMS 风讯CMS 新云CMS SiteServer 热门关键字: 风讯网络动易教程视频下载商业使用免费cms 当前位置 : 主页 > 织梦CMS > 来源:未知 作者:admin 时间:2011-01-04 09:53 浏览: dede采集文章时常用规则中的超链接过滤 dede采集规则大全过滤后缺少了链接文字,这样使的文章内容不通顺,换成下面这两条,只过滤前面的<a>标记过滤网址为指定的网址 这样可以把文章中的所有域名换成你想要的网址 dede采集文章,过滤规则大全,常用规则_dede采集规则大全,优化文章标题添加指定的文字头 但是现在很流行关键词再加标题的形式所以我们可以这样设置 看到没,少了le>下面就用过滤规则替换掉这样就做到了任何地方标题前面加了指定的关键字 过滤指定的一些不想要的文字这样就把文章里有这些字的地方过滤成空了,不过这样做有时文章会读不通,经常会用到互换 过滤一些电话 过滤400电话 [收藏] [推荐] [
===================================================================================================
1.采集去除链接
[Copy to clipboard]CODE:
{dede:trim}dede:trim}
让field:title 标题突破30这个长度,修改代码的方法
找到./include/inc_arcpart_view.php
行291 :
if($titlelen== ) $titlelen = 30;
修改为
if($titlelen== ) $titlelen = 60;
就可以了,然后,你可以这样调用了
{dede:channelArtlist typeid='0' col=1 tablewidth='100%'}
{dede:arclist row= 10 }
[field:title function= cn_substr('@me',38) /]
{/dede:arclist}
{/dede:channelArtlist}
把这个延伸一下:关于inc_arcpart_view.php
function GetArcList($typeid=0,$row=10,$col=1,$titlelen=30,$infolen=160,
$imgwidth=120,$imgheight=90,$listtype= all ,$orderby= default ,$keyword= ,
$innertext= ,$tablewidth= 100 ,$arcid=0,$idlist= )
这里的参数都可以更改你实际需要的模板元素尺寸大小.
2. 采集过虑中去掉链接保留文字的方法!
柏老大的方法是{dede:trim}<a a>{/dede:trim}
这样做会去掉<a hf.......>与</a>之间的字符!这样整个文章就少了部分字符,不完整了!
后来我多次测试,总算找到了正确的使用方法!如下:
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
做成两条采集规则就可以了!
在实际使用中好像(两条一起使用才行!
3. 过滤div
{dede:trim}]*)>{/dede:trim}
{dede:trim}
{/dede:trim}
过滤js
{dede:trim}dede:trim}
过滤未知变量字符
固定(.*)固定
4.dede万能过滤代码
以下是常用的正则表达式标签
{dede:trim}<tbody(.*)>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(.*)>{/dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<tr(.*)>{/dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<td(.*)>{/dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<font(.*)>{/dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(.*)>{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<param(.*)>{/dede:trim}
{dede:trim}<embed(.*)</embed>{/dede:trim}
{dede:trim}<object(.*)</object>{/dede:trim}
{dede:trim}<iframe(.*)</iframe>{/dede:trim}
{dede:trim}<form(.*)</form>{/dede:trim}
{dede:trim}<input(.*)>{/dede:trim}
{dede:trim}<script(.*)</script>{/dede:trim}
{dede:trim}<style(.*)</style>{/dede:trim}
{dede:trim}dede:trim}
以下为不常用的正则表达式标签
{dede:trim}<div(.*)>{/dede:trim}
{dede:trim}</div>{/dede:trim}
{dede:trim}<center(.*)>{/dede:trim}
{dede:trim}</center>{/dede:trim}
{dede:trim}<p(.*)>{/dede:trim}
{dede:trim}</p>{/dede:trim}
{dede:trim}<span(.*)>{dede:trim}
{dede:trim}</span>{dede:trim}
{dede:trim}<img(.*)>{/dede:trim}
5.织梦标题不全,鼠标指向显示全部的代码:
{dede:arclist titlelen='100'}
[field:title function=' ( strlen( @me )>40 ? cn_substr( @me ,40): @me ) '/]
{/dede:arclist}
6.dede/inc/inc_archives_functions.php第100行(flash频道远程flash本地化的BUG)
$cfg_uploaddir = $GLOBALS['media_dir'];
修改成
$cfg_uploaddir = $GLOBALS['cfg_other_medias'];
6.发布时间,来源,作者可以通过@me函数实现,如:在自定义处理接口:处输入 @me = Azure・【博】 就表示来源为 Azure・【博】
7.内容的替换:在所采集的文章内容中有多媒体,使用的是相对路径,采集的时候又不想下载,最好的办法就是将地址替换成媒体的实际地址.可以这样实现,在文章内容规则部分的自定义处理接口:处输入@me=str_replace('src= str1','src= str2',@me);
这样采集出来的文章中的所有的str1就被替换成str2!
===================================================================================================
本文旨在以一个有代表性的文字分页的取样规则和过滤规则为蓝本,通过简单的变通和改动,解决一般性文字分页的采集问题
一、范例部分
范例分页区域代码:
范例分页区域代码:
范例分页区域取样代码:
分页区域取样(匹配):
范例分页内容过滤规则:
分页内容过滤规则:
范例采集内容预览:
范例采集内容预览:
范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过'直接导入人家的代码都不能用',确实如此):
输出结果:
这是全部的代码,可导入试下:
复制代码 代码如下:
{!-- 节点基本信息 --}
{dede:item
imgurl='/upimg' imgdir='../upimg' language='gb2312' typeid='1' macthtype='string'}
{/dede:item}
{!-- 采集列表获取规则 --}
{dede:list source='var' sourcetype='archives'
varstart='' varend=''}
{dede:url value='http://www.xiaocao.com/text/class1/class1/200609/text_28623.html'}{/dede:url}
{dede:need}{/dede:need}
{dede:cannot}{/dede:cannot}
{dede:linkarea}[var:区域]{/dede:linkarea}
{/dede:list}
{!-- 网页内容获取规则 --}
{dede:art}
{dede:sppage sptype='full'}<p><b><font color='red'>[1]</font>[var:分页区域]</b>{/dede:sppage}
{dede:note field='dede_archives.title' value='[var:内容]' comment='文章标题'
isunit='' isdown=''}
{dede:match}<title>[var:内容]</title>{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field='dede_archives.sortrank' value='[var:内容]' comment='排序级别'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field='dede_archives.writer' value='[var:内容]' comment='文章作者'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field='dede_archives.litpic' value='[var:内容]' comment='缩略图'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}@me = @litpic;{/dede:function}
{/dede:note}
{dede:note field='dede_archives.pubdate' value='[var:内容]' comment='发布时间'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}if(@me!= ) @me = GetMkTime(@me);
else @me = time();{/dede:function}
{/dede:note}
{dede:note field='dede_archives.senddate' value='[var:内容]' comment='录入时间'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}@me = time();{/dede:function}
{/dede:note}
{dede:note field='dede_addonarticle.body' value='[var:内容]' comment='文章内容'
isunit='1' isdown=''}
{dede:match}<script language= JavaScript type= text/javascript src= /AD/artcontent.js ></script>[var:内容]<table width= 100% border= 0 cellspacing= 0 cellpadding= 0 >
{/dede:match}
{dede:trim}<p><b>(.*)</b></p>{/dede:trim}
{dede:function}{/dede:function}
{/dede:note}
{dede:note field='dede_archives.source' value='[var:内容]' comment='文章来源'
isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:note}
{/dede:art}
===================================================================================================
1.css 字体简写规则
当使用css定义字体时你可能会这样做:
font-size: 1em;
line-height: 1.5em;
font-weight: bold;
font-style: italic;
font-variant: small-caps;
font-family: verdana,serif;
事实上你可以简写这些属性:
font: 1em/1.5em bold italic small-caps verdana,serif
现在好多了吧,不过有一点要注意:使用这一简写方式你至少要指定font-size和font-family属性,其他的属性(如font-weight, font-style,font-varient)如未指定将自动使用默认值.
2.同时使用两个class
专业仿站团队,我们专注从事于网站改版、专业高真仿站,搜索引擎优化(SEO).我们拥有独到的设计理念、多方位的设计风格、经验丰富的设计团队与技术一流的开发团队,并且具备与多家国内大中型企业的合作经验.本组织储备了一批网站开发高手及专业美工设计人员,我们已有多次成功仿站经验,技术经验过硬,责任心强,工作踏实.可以采用ASP、PHP、.等编程语言及配备的MYSQLACCESSS数据库存储来整体开发及设计各类型大中型网站,网站开发周期短,代码质量和网站整体安全有保证,设计精美,价格合理.
我们承诺,价格绝对优惠!
联系QQ:1377003138
dede采集文章时常用规则中的超链接过滤
{dede:trim replace=dede:trim}
过滤后缺少了链接文字,这样使的文章内容不通顺,换成下面这两条,只过滤前面的标记
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
过滤网址为指定的网址
{dede:trim replace= }www.com|cn|net){/dede:trim}
这样可以把文章中的所有域名换成你想要的网址
优化文章标题添加指定的文字头
标题规则:本来是
但是现在很流行关键词再加标题的形式
所以我们可以这样设置
标题规则:
看到没,少了le> 下面就用过滤规则替换
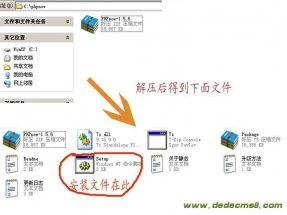
首先我自己庆祝一下,通过自己学习和实践解决了自己的问题~~并把自己的实战全过程拿出来给新手借鉴~~
对于高手,我写这个文章可能有点初级,有什么更好的建议请指点一二,让我和大家都好好学习.因为我是今天才接触 DEDECMS,不过以前经常逛PW,DZ,有这方面的一些模板经验.不过比较这些程序,才发现 DEDECMS模板安装是最不规范的一个,强烈呼吁官方能规范一下模板的发布和安装教程!
由于是实战过程,所以我在附件上传了那个模板文件,模板文件版权属于原作者,感谢他的研制!
下面来一一说明
1.我下载后模板的文件为
===================================================================================================
本文旨在以一个有代表性的文字分页的取样规则和过滤规则为蓝本,通过简单的变通和改动,解决一般性文字分页的采集问题一、范例部分范例分页区域代码:范例分页区域代码:=700) window.open('/upload/20074321296309.gif'); src= /upload/20074321296309.gif onload= if(this.width>'700')this.width='700'; border=0>范例分页区域取样代码: 分页区域取样(匹配):=700) window.open('/upload/20074321298864.gif'); src= /upload/20074321298864.gif onload= if(this.width>'700')this.width='700'; border=0> 范例分页内容过滤规则:分页内容过滤规则:=700) window.open('/upload/20074321298386.gif'); src= /upload/20074321298386.gif onload= if(this.width>'700')this.width='700'; border=0> 范例采集内容预览:范例采集内容预览:=700) window.open('/upload/20074321298685.gif'); src= /upload/20074321298685.gif onload= if(this.width>'700')this.width='700'; border=0>范例全代码(说明:此代码为在原基础上进行更改后的代码,原代码版本不同,直接导入后无效,因此在dede论坛中有许多朋友说过'直接导入人家的代码都不能用',确实如此):输出结果:与原文比较下吧:这是全部的代码,可导入试下:[复制此代码]CODE:{!-- 节点基本信息 --} {dede:item imgurl='/upimg' imgdir='../upimg' language='gb2312' typeid='1' macthtype='string'} {/dede:item} {!-- 采集列表获取规则 --} {dede:list source='var' sourcetype='archives' varstart='' varend=''} {dede:url value='http://www.xiaocao.com/text/class1/class1/200609/text_28623.html'}{/dede:url} {dede:need}{/dede:need} {dede:cannot}{/dede:cannot} {dede:linkarea}[var:区域]{/dede:linkarea} {/dede:list} {!-- 网页内容获取规则 --} {dede:art} {dede:sppage sptype='full'}[1][var:分页区域]{/dede:sppage} {dede:note field='dede_archives.title' value='[var:内容]' comment='文章标题' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}{/dede:function} {/dede:note} {dede:note field='dede_archives.sortrank' value='[var:内容]' comment='排序级别' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = time();{/dede:function} {/dede:note} {dede:note field='dede_archives.writer' value='[var:内容]' comment='文章作者' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}{/dede:function} {/dede:note} {dede:note field='dede_archives.litpic' value='[var:内容]' comment='缩略图' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = @litpic;{/dede:function} {/dede:note} {dede:note field='dede_archives.pubdate' value='[var:内容]' comment='发布时间' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}if(@me!= ) @me = GetMkTime(@me); else @me = time();{/dede:function} {/dede:note} {dede:note field='dede_archives.senddate' value='[var:内容]' comment='录入时间' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}@me = time();{/dede:function} {/dede:note} {dede:note field='dede_addonarticle.body' value='[var:内容]' comment='文章内容' isunit='1' isdown=''} {dede:match}[var:内容] {/dede:match} {dede:trim}(.*)
{/dede:trim} {dede:function}{/dede:function} {/dede:note} {dede:note field='dede_archives.source' value='[var:内容]' comment='文章来源' isunit='' isdown=''} {dede:match}{/dede:match} {dede:function}{/dede:function} {/dede:note} {/dede:art}
===================================================================================================
dedecms采集自动文章摘要规则和方法
1.在采集规则模型里添加1个字段 description 描述成文章摘要
递属表:dede4_archives
2 .建立的新节点就多了一个文章摘要,匹配区域和文章内容的匹配区域一样(因为是取文章的一段),
过滤规则都用上
Copy code
{dede:trim}
{/dede:trim}
{dede:trim}<param(dede:trim}
{dede:trim}<embed(embed>{/dede:trim}
{dede:trim}<embed(dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<object(dede:trim}
{dede:trim}</object>{/dede:trim}
{dede:trim}<OBJECT(OBJECT>{/dede:trim}
{dede:trim}<OBJECT(dede:trim}
{dede:trim}</OBJECT>{/dede:trim}
{dede:trim}<iframe(iframe>{/dede:trim}
{dede:trim}<iframe(dede:trim}
{dede:trim}</iframe>{/dede:trim}
{dede:trim}<IFRAME(IFRAME>{/dede:trim}
{dede:trim}<IFRAME(dede:trim}
{dede:trim}</IFRAME>{/dede:trim}
{dede:trim}<font(font>{/dede:trim}
{dede:trim}<font(dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(a>{/dede:trim}
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<td(td>{/dede:trim}
{dede:trim}<td(dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<tr(tr>{/dede:trim}
{dede:trim}<tr(dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<tbody(tbody>{/dede:trim}
{dede:trim}<tbody>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(table>{/dede:trim}
{dede:trim}<table(dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<img(dede:trim}
{dede:trim}<span(dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}<stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}<br>{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}</p>{/dede:trim}
{dede:trim}<LI>*</LI>{/dede:trim}
{dede:trim} <LI>{/dede:trim}
我不知道不全,大家自行测试
3 .自定义处理接口里面填
Copy code
@me='.substr(@me, 0, 200).'<br><br>'.@me
以上基本ok
4.如果已经有节点不想重新添加节点也可以在更改节点配置里添加这段
Copy code
{dede:note field='dede4_archives.description' value='[var:内容]' comment='文章摘要'
isunit='1' isdown='1'}
{dede:match}<div class= vb id= pzoom >[var:内容]</div>{/dede:match}
{dede:trim}
{/dede:trim}
{dede:trim}<param(dede:trim}
{dede:trim}<embed(embed>{/dede:trim}
{dede:trim}<embed(dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<object(dede:trim}
{dede:trim}</object>{/dede:trim}
{dede:trim}<OBJECT(OBJECT>{/dede:trim}
{dede:trim}<OBJECT(dede:trim}
{dede:trim}</OBJECT>{/dede:trim}
{dede:trim}<iframe(iframe>{/dede:trim}
{dede:trim}<iframe(dede:trim}
{dede:trim}</iframe>{/dede:trim}
{dede:trim}<IFRAME(IFRAME>{/dede:trim}
{dede:trim}<IFRAME(dede:trim}
{dede:trim}</IFRAME>{/dede:trim}
{dede:trim}<font(font>{/dede:trim}
{dede:trim}<font(dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(a>{/dede:trim}
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<td(td>{/dede:trim}
{dede:trim}<td(dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<tr(tr>{/dede:trim}
{dede:trim}<tr(dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<tbody(tbody>{/dede:trim}
{dede:trim}<tbody>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(table>{/dede:trim}
{dede:trim}<table(dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<img(dede:trim}
{dede:trim}<span(dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}<stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
{dede:trim}<br>{/dede:trim}
{dede:trim}</br>{/dede:trim}
{dede:trim}<p>{/dede:trim}
{dede:trim}</p>{/dede:trim}
{dede:trim}<LI>*</LI>{/dede:trim}
{dede:trim} <LI>{/dede:trim}
{dede:function}@me='.substr(@me, 0, 200).'<br><br>'.@me {/dede:function}
{/dede:note}
===================================================================================================
建网站:织梦模板的采集规则教程与过滤替换技巧
一、织梦模板的采集规则教程.
1.首先需要选定采集的网站
例如我们引用网址:以DEDE的官方站做为采集站做示范
2.查看被采集网站的编码. 打开被采集的网页之后,在网页空白点右键-查看源文件就可以看到了.打开如下图 : 在上面<head> </head>代码之间找到 charset 这个,后面就显示网页的编码了,这里是 gb2312
织梦采集规则教程-怎么做网站图片
然后在页面编码处选择和上面相同的编码,这里我们就选择 GB2312 如下图:
织梦采集规则教程2-怎么做网站图片
3.重要的地方:采集列表获取规则具体写法
来源网址写法,很明显pageno是表示分页页码 那么有多页列表的采集就要用 [var:分页] 来替换分页页码, 截图 如下
plus/list.php?tid=10&pageno=[var:分页]
织梦采集规则教程3-怎么做网站图片
织梦采集规则教程4-怎么做网站图片
文章网址需包含和网址不能包含,这两个一般不用写,用于采集列表范围有很多不需要的连接才用到他来做过滤使用. 至于 为什么要在前面加上,这个就不要我说了吧. 如果只有一个列表页,那在来源网址就直接写网址就OK了.
织梦采集规则教程5-怎么做网站图片
注意这里,最关键就是这里.
下面就是 采集获取文章列表的规则写法 ,就是上面打开的被采集页面的源代码文件,找到文章列表之前 和本页面没有其他相同的代码在DedeCms官方站的列表页文章列表之前和之后最近的且没有相同的是 <div class= newslist > 和 <div class= pages > ,分别写入 起始HTML 和 结束HTML ,写法看截图
织梦采集规则教程6-怎么做网站图片
4.采集文章标题,文章内容,文章作者,文章来源等规则写法,分页采集等. 起始HTML 和结束HTML 写法参考第三步中的 获取文章列表的规则写法
织梦采集规则教程7-怎么做网站图片
织梦采集规则教程8-怎么做网站图片
5.下面讲的是如何采集分页内容 :看截图圈着的地方, 文档是否分页 里面选择全部列出的分页列表 起始HTML 和 结束HTML 写法参考第三步中的 获取文章列表的规则写法
织梦采集规则教程9-怎么做网站图片
织梦采集规则教程10-怎么做网站图片
这里本来还有一张截图的,由于论坛配置,他现在显示在最上面. 在文章内容那里点上 分页内容字段 ,不选择就不能采集. 下载字段里的多媒体资源 这个是采集的时候把多媒体资源(视频,软件,图片等)下载到本地,也就是你的网站.这是过滤规则:过滤规则需要用 正则表达式 来写,但是对于新手来说,这个简直是比登天还要难,具体的可以参考:
这个网页
下面教大家一个简单的方法.把下面的 过滤规则 复制到你那里去,几乎就可以了,也可以自己分析一下,说不定你就懂了
引用
{dede:trim}<span(.*)>{/dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim}<div(.*)>{/dede:trim}
{dede:trim}</div>{/dede:trim}
{dede:trim}<li>{/dede:trim}
{dede:trim}</li>{/dede:trim}
{dede:trim}<ul>{/dede:trim}
{dede:trim}</ul>{/dede:trim}
{dede:trim}<font(.*)>{/dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<table(.*)>{/dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<tbody(.*)>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<tr(.*)>{/dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<td(.*)>{/dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<a(.*)>{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<iframe(.*)</iframe>{/dede:trim}
{dede:trim}<style(.*)</style>{/dede:trim}
{dede:trim}<script(.*)</script>{/dede:trim}
{dede:trim}<option(.*)</option>{/dede:trim}
{dede:trim}<select(.*)</select>{/dede:trim}
{dede:trim}<embed(.*)>{/dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<param(.*)</param>{/dede:trim}
{dede:trim}<object(.*)</object>{/dede:trim}
当然 上面这些不能用来采集带有视频的,因为已经过滤了,后面的四行是过滤掉视频的.
6.自定义处理接口. 就是PHP代码.只不过 @ me 表示当前标记值和最终结果 @ body表示原始网页 @ litpic 缩略图 ,按照PHP的写法的就OK了 ,要不懂PHP的话这个我也帮不了你,你可以去慢慢学习.
二、DedeCMS采集规则二:过滤、替换、技巧
1.采集去除链接
[Copy to clipboard]CODE:
{dede:trim}dede:trim}
让field:title 标题突破30这个长度,修改代码的方法
找到./include/inc_arcpart_view.php
行291 :
if($titlelen== ) $titlelen = 30;
修改为
if($titlelen== ) $titlelen = 60;
就可以了,然后,你可以这样调用了
{dede:channelArtlist typeid='0' col=1 tablewidth='100%'}
{dede:arclist row= 10 }
[field:title function= cn_substr('@me',38) /]
{/dede:arclist}
{/dede:channelArtlist}
把这个延伸一下:关于inc_arcpart_view.php
function GetArcList($typeid=0,$row=10,$col=1,$titlelen=30,$infolen=160,
$imgwidth=120,$imgheight=90,$listtype= all ,$orderby= default ,$keyword= ,
$innertext= ,$tablewidth= 100 ,$arcid=0,$idlist= )
这里的参数都可以更改你实际需要的模板元素尺寸大小.
2. 采集过虑中去掉链接保留文字的方法!
柏老大的方法是{dede:trim}<a a>{/dede:trim}
这样做会去掉<a hf.......>与</a>之间的字符!这样整个文章就少了部分字符,不完整了!
后来我多次测试,总算找到了正确的使用方法!如下:
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
做成两条采集规则就可以了!
在实际使用中好像(两条一起使用才行!
3. 过滤div
{dede:trim}]*)>{/dede:trim}
{dede:trim}
{/dede:trim}
过滤js
{dede:trim}dede:trim}
过滤未知变量字符
固定(.*)固定
4.dede万能过滤代码
以下是常用的正则表达式标签
{dede:trim}<tbody(.*)>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(.*)>{/dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<tr(.*)>{/dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<td(.*)>{/dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<font(.*)>{/dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(.*)>{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<param(.*)>{/dede:trim}
{dede:trim}<embed(.*)</embed>{/dede:trim}
{dede:trim}<object(.*)</object>{/dede:trim}
{dede:trim}<iframe(.*)</iframe>{/dede:trim}
{dede:trim}<form(.*)</form>{/dede:trim}
{dede:trim}<input(.*)>{/dede:trim}
{dede:trim}<scrīpt(.*)</scrīpt>{/dede:trim}
{dede:trim}<style(.*)</style>{/dede:trim}
{dede:trim}dede:trim}
以下为不常用的正则表达式标签
{dede:trim}<div(.*)>{/dede:trim}
{dede:trim}</div>{/dede:trim}
{dede:trim}<center(.*)>{/dede:trim}
{dede:trim}</center>{/dede:trim}
{dede:trim}<p(.*)>{/dede:trim}
{dede:trim}</p>{/dede:trim}
{dede:trim}<span(.*)>{dede:trim}
{dede:trim}</span>{dede:trim}
{dede:trim}<img(.*)>{/dede:trim}
5.织梦标题不全,鼠标指向显示全部的代码:
{dede:arclist titlelen='100'}
[field:title function=' ( strlen( @me )>40 ? cn_substr( @me ,40): @me ) '/]
{/dede:arclist}
6.dede/inc/inc_archives_functions.php第100行(flash频道远程flash本地化的BUG)
$cfg_uploaddir = $GLOBALS['media_dir'];
修改成
$cfg_uploaddir = $GLOBALS['cfg_other_medias'];
6.发布时间,来源,作者可以通过@me函数实现,如:在自定义处理接口:处输入 @me = Azure.【博】 就表示来源为 Azure.【博】
7.内容的替换:在所采集的文章内容中有多媒体,使用的是相对路径,采集的时候又不想下载,最好的办法就是将地址替换成媒体的实际地址.可以这样实现,在文章内容规则部分的自定义处理接口:处输入@me=str_replace('src= str1','src= str2',@me);
dedecms 带超连接关键字 如何去掉
全部去
{dede:trim}^<a*'>*</a>${/dede:trim}
===================================================================================================
关键字:dede采集基础教程(四)--过滤规则篇
在这里,我会分批分段的给大家介绍一些dede的使用方法心得.主要是给一些刚刚接触dede的站长朋友们指个路.dede的基本功能在他们的技术文档里面有很详尽的说明,如果花点时间去查看,应该很快就会熟悉起来.这一次我给大家介绍的是dede采集功能的使用,dede的采集功能很受站长们欢迎,但一些刚接触dede的朋友可能会对这个功能感到很陌生,很抗绝.
由于时间的关系,我会陆续的把这个功能分批介绍给大家.
经过前面三篇的介绍,对于dede的采集我们也有基本的了解和操作能力,对于采集简单的内容来说也足够用了.然而对于大多数网站来说,现在广告是网站收入的一个重要来源,因此在网页中常会嵌入广告代码.我们在采集的时候,如何将其过滤掉,从而避免了自己帮别人免费挂广告呢?又例如某些文章里面某些关键词有了他们自己网站上的其他文章链接,你是否愿意让你辛苦采集回来的文章里包含了他的链接?这一切,只需简单的过滤规则,即可给你一篇干净的文章.
dede的过滤规则并不难写,其写法如下面
{dede:trim}这里就是要过滤的内容{/dede:trim}
如果你要过滤的内容比较简单的代码,完全可以直接在 {dede:trim} 和 {/dede:trim} 之间写上,如果比较复杂的就要用到正则了.
1、例如采集中去除内容里的超链接的规则如下:
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
假如要将所有超链接内容都去除,规则是:{dede:trim}<a(a>{/dede:trim}
这两个规则的不同通过下面代码来解释
例如文章代码中包含着如下内容:<a href= # >超链接</a>
通过第一个规则,我们采集来的结果是:超链接
通过第二个规则,我们采集来的结果是:空白,即是将所有内容都过滤掉了.
2、过滤广告
对于广告来说,过滤规则就得针对html中看到的内容使用规则了,例如某些广告仅仅是引用某个JS文件,例如
<script src='/plus/ad_js.php?aid=4′ language='javascript'></script>
这样的规则只需
{dede:trim}<script(.*)>{/dede:trim}
{dede:trim}</script>{/dede:trim}
如果某些广告的内容是JS代码写在<script></script>区间里的,例如GG的广告,那么过滤规则应该是:
{dede:trim}<script>(.*)</script>{/dede:trim}
3、下面是一些常识用的过滤规则
{dede:trim}dede:trim}
{dede:trim}<select(select>{/dede:trim}
{dede:trim}<option(option>{/dede:trim}
{dede:trim}<select(dede:trim}
{dede:trim}</select>{/dede:trim}
{dede:trim}<param(dede:trim}
{dede:trim}<embed(embed>{/dede:trim}
{dede:trim}<embed(dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<object(dede:trim}
{dede:trim}</object>{/dede:trim}
{dede:trim}<OBJECT(
在这里,我会分批分段的给大家介绍一些dede的使用方法心得.主要是给一些刚刚接触dede的站长朋友们指个路.dede的基本功能在他们的技术文档里面有很详尽的说明,如果花点时间去查看,应该很快就会熟悉起来.这一次我给大家介绍的是dede采集功能的使用,dede的采集功能很受站长们欢迎,但一些刚接触dede的朋友可能会对这个功能感到很陌生,很抗绝.由于时间的关系,我会陆续的把这个功能分批介绍给大家.经过前面三篇的介绍,对于dede的采集我们也有基本的了解和操作能力,对于采集简单的内容来说也足够用了.然而对于大多数网站来说,现在广告是网站收入的一个重要来源,因此在网页中常会嵌入广告代码.我们在采集的时候,如何将其过滤掉,从而避免了自己帮别人免费挂广告呢?又例如某些文章里面某些关键词有了他们自己网站上的其他文章链接,你是否愿意让你辛苦采集回来的文章里包含了他的链接?这一切,只需简单的过滤规则,即可给你一篇干净的文章. dede的过滤规则并不难写,其写法如下面{dede:trim}这里就是要过滤的内容{/dede:trim}如果你要过滤的内容比较简单的代码,完全可以直接在 {dede:trim} 和 {/dede:trim} 之间写上,如果比较复杂的就要用到正则了. 1、例如采集中去除内容里的超链接的规则如下:{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}假如要将所有超链接内容都去除,规则是:{dede:trim}dede:trim}这两个规则的不同通过下面代码来解释例如文章代码中包含着如下内容:超链接通过第一个规则,我们采集来的结果是:超链接通过第二个规则,我们采集来的结果是:空白,即是将所有内容都过滤掉了. 2、过滤广告对于广告来说,过滤规则就得针对html中看到的内容使用规则了,例如某些广告仅仅是引用某个JS文件,例如这样的规则只需{dede:trim}{/dede:trim}{dede:trim}{/dede:trim}如果某些广告的内容是JS代码写在区间里的,例如GG的广告,那么过滤规则应该是:{dede:trim}(.*){/dede:trim} 3、下面是一些常识用的过滤规则 {dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}dede:trim}{dede:trim}]*)>{/dede:trim}{dede:trim}{/dede:trim}{dede:trim}]*)>
=========================================================================================
超级详尽的织梦采集教程
看到很多网友都为织梦(DEDE CMS)的采集教程头疼,的确,官方出的教程太笼统了,什么都没说,换个网站你什么都做不了,这个教程是最详尽的教程,让你一看即会
首先我们打开织梦后台点击 采集mm采集节点管理mm增加新节点
这里我们以采集普通文章为例,我们选择普通文章,然后确定
我们进入了采集的设置页面,填写节点名称,就是给这个新节点取个名字,这里你可以任意填写.
然后打开你想要采集的文章列表页,这里我们以织梦官网为例 打开这个页面,右键mm查看源文件
找到目标页面编码,就在charset后面
页面基本信息其他的一般就不用管了,填完了如图
现在我们来填写列表网址获取规则
我们发现了他们除了49_后面的数字不一样,其他的都一样,所以我们可以这样写
就是把1换成了(*) 因为这里只有2页,所以我们就填从1到2 每页递增当然是1了,2-1...是等于1吧
这里我们就填写完了
可能大家采集的有些列表没有规则,那就只有手工指定列表网址了,如图
每行写一个页面地址
列表规则写完了,我们就开始写文章网址匹配规则了,回到文章列表页
右键查看源文件 找到区域开始的HTML,就是找文章列表开始的标志.
我们很容易的找到了如图中的 新闻列表 .从这里开始,后面就是文章列表里
我们再找文章列表结束的HTML
就是这个了,一个很容易找到的标志
如果链接中含有图片:
不处理 采集为缩略图 这里根据自己的需要选择
对区域网址进行再次筛选:
(使用正则表达式)
必须包含: (优先级高于后者)
不能包含:
打开源文件,我们可以很清楚的看到,文章链接都是以.html结束的
所以,我们在必须包含后面填.html 如果遇到有些列表很麻烦,还可以填写后面的不能包含
我们点击保存设置进入下一步,可以看到我们获得的文章网址
看到这些就是对的了,我们保存信息进入下一步设置内容字段获取规则
我们看看文章有没有分页,随便进入一篇文章看看..我们看到这里的文章没有分页
所以这里的我们就默认了
我们现在来找文章标题等等 随便进入一篇文章,右键查看源文件
看看这些
依照源码填写
我们再来填写文章内容的开始,结束
和上面的一样,找到开始和结束标志
开始:
结束:
你想过滤文章中的什么内容就到过滤规则里写吧,比如要过滤文章中的图片
选择常用规则
再勾选IMG
然后确定
这样我们就把正文中的图片过滤了
设置完毕后点保存设置并预览
这样一个采集规则就写好了,很简单吧有些网站很难写,可要多下点功夫了哦
我们点保存并开始采集mm开始采集网页 一会的功夫就采集完了
我们看看我们采集到的文章
看来是成功了,我们导出数据吧
首先选择要导入到的栏目,按 请选择那里即可在弹出的窗口中选择你需要导入的栏目发布选项这里一般默认即可,除非你不想马上发布.每批导入默认是30条,这里修改与否都无所谓,附带选项一般选排除重复标题 ,至于自动生成HTML那个选项建议先别生成,因为我们还要去批量提取摘要和关键字.
===================================================================================================
dedecms采集过滤规则大全详解
dedecms采集系统确实很不错,可以免去一些站长手工添加信息的麻烦,设置一下采集规则、采集点,然后点采集,OK,几百篇文章就搞定了!呵呵,确实很省事的!下面介绍几种常用的采集规则的过滤方法:
应用示例一:标题中空格的过滤
经常在采集文章的时候,标题文字里面有空格,采回来后应用很是麻烦,所以需要在过滤处添加下面正则过滤
{dede:trim} {/dede:trim}
应用示例二:来源作者中连接的过滤
在采集文章的时候,有的系统里面作者或者来源处都有连接,直接采集的话将连接采集回来了,然后由于这两个字段有限制,通常会造成需要采集的内容没有采集回来,所以需要在过滤处添加下面正则过滤
{dede:trim}<a(a>{/dede:trim}
应用示例三:文章内容中连接以及其他广告代码的过滤
这个就不用说了,当需要对所有东西过滤的时候,直接用上面所有的代码过滤就可以,但是实际应用中,我们只需要对连接、动画、调用等进行过滤.(这个需要按照对方内容里面具体含有什么代码来具体操作)
一般的只有链接,使用二中的代码进行过滤就可以了,但是实际上一般的网站现在都在内容里面加有广告等,所以采取下面的过滤正则就可以完成过滤:
{dede:trim}<a(a>{/dede:trim}
{dede:trim}<IFRAME(IFRAME>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<script(script>{/dede:trim}
应用示例四:过滤GG广告代码
其实这个就是在上面的内容过滤,但是很多论坛里的网友经常问这个,所以单独作为一个应用列出来:
{dede:trim}<script(script>{/dede:trim}
下面是在综合论坛上网友的各种正则的一个全集:
{dede:trim}
{/dede:trim}
{dede:trim}<param(dede:trim}
{dede:trim}<embed(embed>{/dede:trim}
{dede:trim}<embed(dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<object(dede:trim}
{dede:trim}</object>{/dede:trim}
{dede:trim}<OBJECT(OBJECT>{/dede:trim}
{dede:trim}<OBJECT(dede:trim}
{dede:trim}</OBJECT>{/dede:trim}
{dede:trim}<iframe(iframe>{/dede:trim}
{dede:trim}<iframe(dede:trim}
{dede:trim}</iframe>{/dede:trim}
{dede:trim}<IFRAME(IFRAME>{/dede:trim}
{dede:trim}<IFRAME(dede:trim}
{dede:trim}</IFRAME>{/dede:trim}
{dede:trim}<font(font>{/dede:trim}
{dede:trim}<font(dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(a>{/dede:trim}
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<td(td>{/dede:trim}
{dede:trim}<td(dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<tr(tr>{/dede:trim}
{dede:trim}<tr(dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<tbody(tbody>{/dede:trim}
{dede:trim}<tbody>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(table>{/dede:trim}
{dede:trim}<table(dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<img(dede:trim}
{dede:trim}<span(dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}<stong>{/dede:trim}
{dede:trim}</stong>{/dede:trim}
好了,上面四种应用基本上涵盖了采集的各种应用,掌握了这个,过滤基本上就不用求人了!
dede采集过程中最麻烦的莫过于采集的正则过滤函数的编写.说实在的,dede在这点上和很多ASP CMS系统比如说动易等,采集的时候直接选择几个选项就可以了,简单的完成想过滤的东西.不过他们只局限于对文章内容的过滤不是很好.而DEDE却能对所有采集的字段进行过滤,功能上弥补了易用性的缺陷,期待柏拉图在后续版本中加上选择性过滤功能.
下面是在综合正则的一个全集:
{dede:trim}
{/dede:trim}
{dede:trim} ]*)>{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim} ]*)>{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
]*)>{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}
]*)>{/dede:trim}
{dede:trim}
{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim} {/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}{/dede:trim}
应用示例一:标题中空格的过滤
经常在采集文章的时候,标题文字里面有空格,采回来后应用很是麻烦,所以需要在过滤处添加下面正则过滤
{dede:trim} {/dede:trim}
应用示例二:来源作者中连接的过滤
在采集文章的时候,有的系统里面作者或者来源处都有连接,直接采集的话将连接采集回来了,然后由于这两个字段有限制,通常会造成需要采集的内容没有采集回来,所以需要在过滤处添加下面正则过滤
{dede:trim}dede:trim}
应用示例三:文章内容中连接以及其他广告代码的过滤
这个就不用说了,当需要对所有东西过滤的时候,直接用上面所有的代码过滤就可以,但是实际应用中,我们只需要对连接、动画、调用等进行过滤.(这个需要按照对方内容里面具体含有什么代码来具体操作)
一般的只有链接,使用二中的代码进行过滤就可以了,但是实际上一般的网站现在都在内容里面加有广告等,所以采取下面的过滤正则就可以完成过滤:
{dede:trim}dede:trim}
{dede:trim}dede:trim}
{dede:trim}dede:trim}
{dede:trim}dede:trim}
应用示例四:过滤GG广告代码
其实这个就是在上面的内容过滤,但是很多论坛里的网友经常问这个,所以单独作为一个应用列出来:
{dede:trim}dede:trim} (转)
想快速增加 人人网 聚友网 新浪网等博客人气的请联系我
还有 想批量转帖 批量浏览日志 各种投票定制也可联系我
想通过网络赚钱还没有入门的朋友可以和我共同讨论.
===================================================================================================
另外分页的话,分页链接区域匹配规则这里写好就ok了{dede:trim}<span(.*)>{/dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim}<div(.*)>{/dede:trim}
{dede:trim}</div>{/dede:trim}
{dede:trim}<li>{/dede:trim}
{dede:trim}</li>{/dede:trim}
{dede:trim}<ul>{/dede:trim}
{dede:trim}</ul>{/dede:trim}
{dede:trim}<font(.*)>{/dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<table(.*)>{/dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<tbody(.*)>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<tr(.*)>{/dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<td(.*)>{/dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<a(.*)>{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<iframe(.*)</iframe>{/dede:trim}
{dede:trim}<style(.*)</style>{/dede:trim}
{dede:trim}<script(.*)</script>{/dede:trim}
{dede:trim}<option(.*)</option>{/dede:trim}
{dede:trim}<select(.*)</select>{/dede:trim}
{dede:trim}<img(.*)>{/dede:trim}
{dede:trim}</img>{/dede:trim}
{dede:trim}<center(.*)>{/dede:trim}
{dede:trim}</center>{/dede:trim}
{dede:trim}<input(.*)>{/dede:trim}
{dede:trim}</input>{/dede:trim}
{dede:trim}<form(.*)>{/dede:trim}
{dede:trim}</form>{/dede:trim}
{dede:trim}</html>{/dede:trim}
{dede:trim}</body>{/dede:trim}
{dede:trim}<table(.*)</table>{/dede:trim}
楼上的 能帮我采集文章吗?
你qq多少?
顶,终于找到正确的了,谢谢楼主
===================================================================================================
<table(table>|<td>|</td>|<tbody>|</tbody>|<tr>|</tr>
正则: width=\ [0-9][0-9][0-9]\ | width=[0-9][0-9][0-9]| height=\ [0-9][0-9][0-9]\ | height=[0-9][0-9][0-9],说明:过虑height、Width.
正则:<div style=div div>|<div>,注意:匹配<div style= >或者<div id= >.
正则: style=style=[^ ]*,注意:匹配Style= border:
正则:<style(style> ,注意:匹配<style type= text/css ></style>
正则:<font [^>]*>|<font>|</font>|<strong [^>]*>|<strong>|</strong> ,注意:匹配<font>和<strong>
正则: border= [0-9] | border=[0-9],注意:匹配border=
正则:<span [^>]*>|<span>|</span> ,注意:匹配<span>
正则: id=[^ ]*| id=注意:匹配id=
正则: title=[0-9][^ ]*| title=\ [0-9]alt=[0-9][^ ]*| alt=\ [0-9]alt=[a-z][^ ]*| alt=\ [a-z]注意:匹配Title或者alt
正则:说明:匹配HTML注释
正则:<script(script>,说明:匹配<script></script>之间的全部内容
正则: class=[a-z]class=\ [a-z]说明:清理class= ,经过充分测试
正则:<table(table>|<td>|</td>|<tbody>|</tbody>|<tr>|</tr>
正则:<h2 [^>]*>|<h2>|</h2>| align=left|<em>|</em>|<center>|</center>|<a(a>
===================================================================================================
查看需要采集页面的代码,所需屏蔽部分所使用的标签不同分别按下表配置不痛的过滤规则即可.DEDECMS的过滤变量的代表符号和别的采集系统有些不同,PS:为了使本站输出的外链接减少,建议屏蔽了href的链接部分,当然假如是希望保持原貌尊重原创,可以保留.
{dede:trim}<param(dede:trim}
{dede:trim}<embed(embed>{/dede:trim}
{dede:trim}<embed(dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<object(object>{/dede:trim}
{dede:trim}<object(dede:trim}
{dede:trim}</object>{/dede:trim}
{dede:trim}<OBJECT(OBJECT>{/dede:trim}
{dede:trim}<OBJECT(dede:trim}
{dede:trim}</OBJECT>{/dede:trim}
{dede:trim}<iframe(iframe>{/dede:trim}
{dede:trim}<iframe(dede:trim}
{dede:trim}</iframe>{/dede:trim}
{dede:trim}<IFRAME(IFRAME>{/dede:trim}
{dede:trim}<IFRAME(dede:trim}
{dede:trim}</IFRAME>{/dede:trim}
{dede:trim}<font(font>{/dede:trim}
{dede:trim}<font(dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<a(a>{/dede:trim}
{dede:trim}<a(dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<td(td>{/dede:trim}
{dede:trim}<td(dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<tr(tr>{/dede:trim}
{dede:trim}<tr(dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<tbody(tbody>{/dede:trim}
{dede:trim}<tbody>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<table(table>{/dede:trim}
{dede:trim}<table(dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}</p>{/dede:trim}
{dede:trim}<p style= text-indent:24px; >{/dede:trim}
有这些代码大部分的广告和对采集后生成页面的不利因素都可以过滤掉了.
===================================================================================================
在进行页面的DIV+CSS排版时,遇到IE6(当然有时Firefox下也会偶遇)浏览器中的图片元素img下出现多余空白的问题绝对是常见的对於该问题的解决方法也是「见机行事」,根据原因的不同要用不同的解决方法,这里把解决直接把解决image图片布局下边的多余空隙的BUG的常用方法归纳, 供大家参考.
1、将图片转换为块级对像
即,设置img为:
display:block;
在本例中添加一组CSS代码:
#sub img {display:block;}
2、设置图片的垂直对齐方式
即设置图片的vertical-align属性为「top,text-top,bottom,text-bottom」也可以解决.如本例中增加一组CSS代码:
#sub img {vertical-align:top;}
3、设置父对象的文字大小为0px
1 网页成功的首要条件便是主题清晰.如果你只不过是做一个个人网页,你的内容很杂,这也无可厚非.如果你想吸引更多人,就要写得专业点,要有特色,不要把一些毫无关系的内容放在一起,不如做多一个网站.个人的精力有限的.尝试做一个精而专的网站,既可以使你的知识和能力获得更大的提升,网友也可以从中受益.
2 不要制作一些无聊或言之无物的网站,网络上这类网页很多,若你不洁身自爱也加入的话,实属不智.可尝试制作有意义的网页,如个人介绍、收藏、明星网页等等,对于初学者,网页的主题、取材是最大的困惑,不妨多看看别人的网页规划及内容.
3 不要使用本地化、口语化的文字,别以为所有的浏览者都能看懂这些所谓的亲切的口语.个性的反映不只在于网页的整体设计,你的文字表达风格也是一个非常直接的因素.像我这些广东籍的网页设计者尤需注意.
关于外观的禁忌
1 不要先决定网页的外观,然后强迫自己甚至是强迫别人去适应它.应该从网站的浏览者、网站要传达的信息以及网站的发展目标
断头台问题(IE/Win Guillotine bug)是国外的css设计者给这个问题起的一个非常形象的名字,就如同断头台一样,对象被无情的切断了一部分,不过与之相反的是,断头台问题中的对象切断的不是对象的头部,而是对象的底部.xhtml编码(演示):
XML
前推荐遵循的是W3C于2000年10月6日发布的XML1.0和HTML一样,XML同样来源于SGML,但XML是一种能定义其它语言的语.
XML最初设计的目的是弥补HTML的不足,以强大的扩展性满足网络信息发布的需要,后来逐渐用于网络数据的转换和描述.
链接1
链接2
链接3
链接4
这段代码结构由三部分组成,一个是主对象#layput,主框架中有#left为左浮动对象,右侧为普通的链接文字,类似于左右分栏的二栏式布局.css编码:
a:hover {
background-color:#fff;
1.css 字体简写规则
当使用css定义字体时你可能会这样做:
font-size: 1em;
line-height: 1.5em;
font-weight: bold;
font-style: italic;
font-variant: small-caps;
font-family: verdana,serif;
事实上你可以简写这些属性:
font: 1em/1.5em bold italic small-caps verdana,serif
现在好多了吧,不过有一点要注意:使用这一简写方式你至少要指定font-size和font-family属性,其他的属性(如font-weight, font-style,font-varient)如未指定将自动使用默认值.
2.同时使用两个class
dede采集文章时常用规则中的超链接过滤
{dede:trim replace=dede:trim}
过滤后缺少了链接文字,这样使的文章内容不通顺,换成下面这两条,只过滤前面的标记
{dede:trim}]*)>{/dede:trim}
{dede:trim}{/dede:trim}
过滤网址为指定的网址
{dede:trim replace= }|cn|net){/dede:trim}
这样可以把文章中的所有域名换成你想要的网址