一、概述
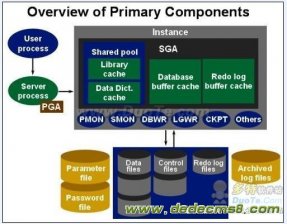
在《Oracle内存结构研究-PGA篇》一文中提到,PGA是一个服务器进程的专用的私有内存区,而SGA则是共享内存区。
SGA由多个部分组成:
1, 固定SGA(Fixed SGA)
2, 块缓冲区(Db cache)
3, 重做日志缓冲区(Redo log buffer)
4, Java池(Java pool)
5, 大池(Large pool)
6, 共享池(Shared pool)
7, 流池(Stream pool)
有如下参数控制共享池相关组件大小:
1, JAVA_POOL_SIZE:控制Java池大小。
2, SHARED_POOL_SIZE:9i中控制共享池中占用最大的部分,10g以上控制共享池大小。
3, LARGE_POOL_SIZE:控制大池大小。
4, DB_*K_CACHE_SIZE:控制不同块大小的缓冲区大小。
5, LOG_BUFFER:控制重做日志缓冲区大小。
6, SGA_TARGET:10g以上控制自动SGA内存管理的总内存大小。
7, SGA_MAX_SIZE:控制SGA可以达到的最大大小,改变需重启数据库。
下面将详细介绍各个部分的作用和推荐设置。
二、SGA各组件作用
1, 固定SGA:
顾名思义,是一段不变的内存区,指向SGA中其他部分,Oracle通过它找到SGA中的其他区,可以简单理解为用于管理的一段内存区。
2, 块缓冲区:
查询时,Oracle会先把从磁盘读取的数据放入内存,以后再查询相关数据时不用再次读取磁盘。插入和更新时,Oracle会现在该区中缓存数据,之后批量写到硬盘中。通过块缓冲区,Oracle可以通过内存缓存提高磁盘的I/O性能。
块缓冲区中有三个区域:
默认池(Default pool):所有数据默认都在这里缓存。
保持池(Keep pool):用来缓存需要多次重用的数据。
回收池(Recycle pool):用来缓存很少重用的数据。
原来只有一个默认池,所有数据都在这里缓存。这样会产生一个问题:大量很少重用的数据会把需重用的数据“挤出”缓冲区,造成磁盘I/O增加,运行速度下降。后来分出了保持池和回收池根据是否经常重用来分别缓存数据。
这三部分内存区需要手动确定大小,并且之间没有共享。例如:保持池中已经满了,而回收池中还有大量空闲内存,这时回收池的内存不会分配给保持池。
9i开始,还可以设置db_nk_cache。9i之前数据库只能使用相同的块大小。9i开始同一个数据库可以使用多种块大小 (2KB,4KB,8KB,16KB,32KB),这些块需要在各自的db_nk_cache中缓存。如果为不同的表空间指定了不同的块大小,需要为其设 置各自的缓冲区。
3, 重做日志缓冲区(Redo log buffer):
数据写到重做日志文件之前在这里缓存,在以下情况中触发:
每隔3秒
缓存达到1MB或1/3满时
用户提交时
缓冲区的数据写入磁盘前
4, Java池(Java pool):
在数据库中运行Java代码时用到这部分内存。例如:编写Java存储过程在服务器内运行。需要注意的是,该内存与常见的Java编写的B/S系统并没关系。用JAVA语言代替PL/SQL语言在数据库中写存储过程才会用到这部分内存。
5, 大池(Large pool):
下面三种情况使用到大池:
并行执行:存放进程间的消息缓冲区
RMAN:某些情况下用于磁盘I/O缓冲区
共享服务器模式:共享服务器模式下UGA在大池中分配(如果设置了大池)
6, 共享池(Shared pool)
共享池是SGA中最重要的内存段之一。共享池太大和太小都会严重影响服务器性能。
SQL和PL/SQL的解释计划、代码,数据字典数据等等都在这里缓存。
SQL 和PL/SQL代码在执行前会进行“硬解析”来获得执行计划及权限验证等相关辅助操作。“硬解析”很费时间。对于响应时间很短的查询,“硬解析”可以占到 全部时间的2/3。对于响应时间较长的统计等操作,“硬解析”所占用的时间比例会下降很多。执行计划及所需的数据字典数据都缓存在共享池中,让后续相同的 查询可以减少很多时间。
不使用“绑定变量”导致:
系统需要花费大量的资源去解析查询。
共享池中的代码从不重用,系统花费很大代价管理这部分内存。
关于共享变量的优缺点讨论已经超过了这篇文章的范畴,简单来讲,响应时间短的查询要使用共享变量,响应时间长的统计不使用共享变量。
需要注意的是,SHARED_POOL_SIZE参数在9i中控制共享池中占用最大的部分,10g以上控制共享池总大小。
7, 流池(Stream pool)
9iR2以上增加了“流”技术,10g以上在SGA中增加了流池。流是用来共享和复制数据的工具。