SQL Server数据库操作中,在2005以上的版本新增加了一个APPLY表运算符的功能,新增的APPLY表运算符把右表表达式应用到左表表达式中的每一行。它不像JOIN那样先计算那个表表达式都可以,APPLY必选先逻辑地计算左表达式。这种计算输入的逻辑顺序允许吧右表达式关联到左表表达式。
APPLY有两种形式,一个是OUTER APPLY,一个是CROSS APPLY,区别在于指定OUTER,意味着结果集中将包含使右表表达式为空的左表表达式中的行,而指定CROSS,则相反,结果集中不包含使右表表达式为空的左表表达式中的行。
理解CROSS APPLY
比如:LargeTable表中的某一列存储的数据是以“:”号分隔的数据,我们处理的时候,可能要先把这个值,先分隔,然后把分隔后的每个值单独一行放在一张表中,然后对这个表做处理。这只是用其中一行做的处理,如果我们把表中多行都做这样的处理,把多行以:号分隔的数值都放在一个表中,该怎么处理呢?
用APPLY表运算符一行语句就能处理以上操作。
- SELECT
- a
- FROM
- dbo.LargeTable AS LT --实际表
- CROSS APPLY
- dbo.Split(LT.Name,':') --自定义表值函数,完成字符串分隔
- WHERE
- a <> '' --去掉结果表中a字段为空的数据
- -----------字符串分隔函数-------------
- CREATE Function [dbo].[Split]
- (
- @Sql varchar(8000),
- @Splits varchar(10)
- )
- returns @temp Table (a varchar(100))
- As
- Begin
- Declare @i Int
- Set @Sql = RTrim(LTrim(@Sql))
- Set @i = CharIndex(@Splits,@Sql)
- While @i >= 1
- Begin
- Insert @temp Values(Left(@Sql,@i-1))
- Set @Sql = SubString(@Sql,@i+1,Len(@Sql)-@i)
- Set @i = CharIndex(@Splits,@Sql)
- End
- If @Sql <> ''
- Insert @temp Values (@Sql)
- Return
- End
- ------------调用示例-------------
- SELECT
- *
- FROM
- dbo.Split('581::579::519::279::406::361::560',':')
APPLY的执行过程:它先逻辑计算左表表达式,然后把右表达式应用到左表表达式的每一行。实际是把外部查询的列引用作为参数传递给表值函数。
我们知道 SQL Server2000 中有个 cross join 是用于交叉联接的。实际上SQL Server 2005 新增 cross apply 和 outer apply 联接语句是用于交叉联接表值函数(返回表结果集的函数)的,更重要的是这个函数的参数是另一个表中的字段。
这个解释可能有些含混不请,请看下面的例子:
- -- 1. cross join 联接两个表
- select *
- from TABLE_1 as T1
- cross join TABLE_2 as T2
- -- 2. cross join 联接表和表值函数,表值函数的参数是个“常量”
- select *
- from TABLE_1 T1
- cross join FN_TableValue(100)
- -- 3. cross join 联接表和表值函数,表值函数的参数是“表T1中的字段”
- select *
- from TABLE_1 T1
- cross join FN_TableValue(T1.column_a)
- Msg 4104, Level 16, State 1, Line 1
- The multi-part identifier "T1.column_a" could not be bound.
最后的这个查询的语法有错误。在cross join 时,表值函数的参数不能是表 T1 的字段, 为啥不能这样做呢?我猜可能微软当时没有加这个功能:),后来有客户抱怨后, 于是微软就增加了 cross apply 和 outer apply 来完善。
请看 cross apply, outer apply 的例子:
- -- 4. cross apply
- select *
- from TABLE_1 T1
- cross apply FN_TableValue(T1.column_a)
- -- 5. outer apply
- select *
- from TABLE_1 T1
- outer apply FN_TableValue(T1.column_a)
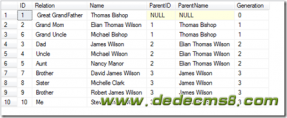
cross apply 和 outer apply 对于 T1 中的每一行都和派生表(表值函数根据T1当前行数据生成的动态结果集)做了一个交叉联接。cross apply 和 outer apply 的区别在于:如果根据 T1 的某行数据生成的派生表为空,cross apply 后的结果集 就不包含 T1 中的这行数据,而 outer apply 仍会包含这行数据,并且派生表的所有字段值都为 NULL。
下面的例子摘自微软 SQL Server 2005 联机帮助,它很清楚的展现了 cross apply 和 outer apply 的不同之处:
- -- cross apply query
- SELECT *
- FROM Departments AS D
- CROSS APPLY fn_getsubtree(D.deptmgrid) AS ST
- deptid deptname deptmgrid empid empname mgrid lvl
- ----------- ----------- ----------- ----------- ----------- ----------- ------
- 1 HR 2 2 Andrew 1 0
- 1 HR 2 5 Steven 2 1
- 1 HR 2 6 Michael 2 1
- 2 Marketing 7 7 Robert 3 0
- 2 Marketing 7 11 David 7 1
- 2 Marketing 7 12 Ron 7 1
- 2 Marketing 7 13 Dan 7 1
- 2 Marketing 7 14 James 11 2
- 3 Finance 8 8 Laura 3 0
- 4 R&D 9 9 Ann 3 0
- 5 Training 4 4 Margaret 1 0
- 5 Training 4 10 Ina 4 1
(12 row(s) affected)
- -- outer apply query
- SELECT *
- FROM Departments AS D
- OUTER APPLY fn_getsubtree(D.deptmgrid) AS ST
- deptid deptname deptmgrid empid empname mgrid lvl
- ----------- ----------- ----------- ----------- ----------- ----------- ------
- 1 HR 2 2 Andrew 1 0
- 1 HR 2 5 Steven 2 1
- 1 HR 2 6 Michael 2 1
- 2 Marketing 7 7 Robert 3 0
- 2 Marketing 7 11 David 7 1
- 2 Marketing 7 12 Ron 7 1
- 2 Marketing 7 13 Dan 7 1
- 2 Marketing 7 14 James 11 2
- 3 Finance 8 8 Laura 3 0
- 4 R&D 9 9 Ann 3 0
- 5 Training 4 4 Margaret 1 0
- 5 Training 4 10 Ina 4 1
- 6 Gardening NULL NULL NULL NULL NULL
注意outer apply 结果集中多出的最后一行。 当 Departments 的最后一行在进行交叉联接时:deptmgrid 为 NULL,fn_getsubtree(D.deptmgrid) 生成的派生表中没有数据,但 outer apply 仍会包含这一行数据,这就是它和 cross join 的不同之处。
下面是完整的测试代码,你可以在 SQL Server 2005 联机帮助上找到:
-- create Employees table and insert values
IF OBJECT_ID('Employees') IS NOT NULL
DROP TABLE Employees
GO
CREATE TABLE Employees
(
empid INT NOT NULL,
mgrid INT NULL,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL
)
GO
IF OBJECT_ID('Departments') IS NOT NULL
DROP TABLE Departments
GO
-- create Departments table and insert values
CREATE TABLE Departments
(
deptid INT NOT NULL PRIMARY KEY,
deptname VARCHAR(25) NOT NULL,
deptmgrid INT
)
GO
-- fill datas
INSERT INTO employees VALUES (1,NULL,'Nancy',00.00)
INSERT INTO employees VALUES (2,1,'Andrew',00.00)
INSERT INTO employees VALUES (3,1,'Janet',00.00)
INSERT INTO employees VALUES (4,1,'Margaret',00.00)
INSERT INTO employees VALUES (5,2,'Steven',00.00)
INSERT INTO employees VALUES (6,2,'Michael',00.00)
INSERT INTO employees VALUES (7,3,'Robert',00.00)
INSERT INTO employees VALUES (8,3,'Laura',00.00)
INSERT INTO employees VALUES (9,3,'Ann',00.00)
INSERT INTO employees VALUES (10,4,'Ina',00.00)
INSERT INTO employees VALUES (11,7,'David',00.00)
INSERT INTO employees VALUES (12,7,'Ron',00.00)
INSERT INTO employees VALUES (13,7,'Dan',00.00)
INSERT INTO employees VALUES (14,11,'James',00.00)
INSERT INTO departments VALUES (1,'HR',2)
INSERT INTO departments VALUES (2,'Marketing',7)
INSERT INTO departments VALUES (3,'Finance',8)
INSERT INTO departments VALUES (4,'R&D',9)
INSERT INTO departments VALUES (5,'Training',4)
INSERT INTO departments VALUES (6,'Gardening',NULL)
GO
--SELECT * FROM departments
-- table-value function
IF OBJECT_ID('fn_getsubtree') IS NOT NULL
DROP FUNCTION fn_getsubtree
GO
CREATE FUNCTION dbo.fn_getsubtree(@empid AS INT)
RETURNS TABLE
AS
RETURN(
WITH Employees_Subtree(empid, empname, mgrid, lvl)
AS
(
-- Anchor Member (AM)
SELECT empid, empname, mgrid, 0
FROM employees
WHERE empid = @empid
UNION ALL
-- Recursive Member (RM)
SELECT e.empid, e.empname, e.mgrid, es.lvl+1
FROM employees AS e
join employees_subtree AS es
ON e.mgrid = es.empid
)
SELECT * FROM Employees_Subtree
)
GO
-- cross apply query
SELECT *
FROM Departments AS D
CROSS APPLY fn_getsubtree(D.deptmgrid) AS ST
-- outer apply query
SELECT *
FROM Departments AS D
OUTER APPLY fn_getsubtree(D.deptmgrid) AS ST